
Synthetic Data Generation Market Size, AI Training Data Trends and Forecast 2026–2034
- Ajit Kumar
- Mar 27
- 4 min read

Synthetic Data Generation Market Overview Analysis By Fortune Business Insights
Market Summary
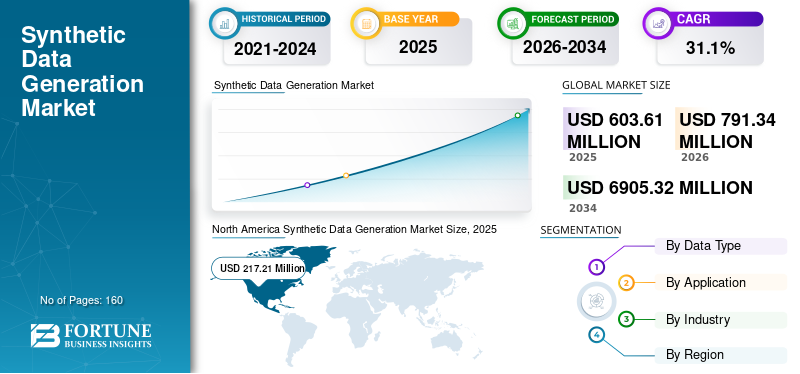
According to Fortune Business Insights: The global synthetic data generation market was valued at USD 603.61 million in 2025. The market is projected to grow from USD 791.34 million in 2026 to USD 6905.32 million by 2034, exhibiting a CAGR of 31.10% during the forecast period. North America dominated the synthetic data generation market with a market share of 35.99% in 2025.
Synthetic data generation is the process of creating data algorithmically — rather than from real-world observations — using statistical modeling, simulations, and techniques such as Generative Adversarial Networks (GANs). The resulting datasets serve as substitutes for real operational data in training machine learning models, validating mathematical models, and conducting data testing. Industry experts have projected that by 2024, approximately 60% of data used to develop AI and analytics projects would be synthetically generated, reflecting the technology's growing centrality in modern data pipelines.
Get a Sample Research PDF: https://www.fortunebusinessinsights.com/enquiry/request-sample-pdf/108433
Key Market Trends
A defining trend shaping the market is the surge in deployment of Large Language Models (LLMs). Models such as OpenAI's GPT-3 — with 175 billion machine learning parameters — generate vast conversational and text datasets that power applications across retail, healthcare, technology, and other sectors. These language models are deployed for text generation, image annotation, fraud detection, conversational AI, and code generation, all of which drive continuous demand for high-quality synthetic training data.
Driving Factors
The foremost growth driver is escalating demand for data privacy and security. Real-world data is increasingly inaccessible due to compliance requirements imposed by frameworks such as the General Data Protection Regulation (GDPR), the California Consumer Privacy Act (CCPA), and the Health Insurance Portability and Accountability Act (HIPAA). Synthetic data offers a privacy-safe alternative that retains the statistical characteristics of real datasets while eliminating the risk of exposing sensitive information. In April 2023, Singapore-based startup Betterdata announced its use of synthetic data that mirrors real-world dataset structures without disclosing private individual information — illustrating the practical application of this approach for securing data and improving machine learning model performance.
Restraining Factors
The principal challenge constraining market growth is the difficulty of ensuring data accuracy and realism. Synthetic datasets, while effective for many applications, often struggle to capture the granular nuances of real-world imagery and specialized models. Furthermore, because synthetic data is derived from real-world data that itself evolves over time, maintaining dataset relevance and accuracy requires ongoing updates and validation. This continuous maintenance burden represents a significant operational challenge for organizations relying on synthetic data at scale.
Segmentation Analysis
By Data Type: The text data segment holds the largest market share, driven by the rapid proliferation of natural language generation systems and advanced machine learning models. Tabular data is expected to grow at the highest CAGR, as businesses increasingly rely on structured synthetic data — often generated via GANs — to address privacy concerns. Analysts project that synthetic tabular data used for AI model training will grow approximately three times faster than real structured data by 2030.
By Application: Test data management commands the largest application share, driven by the need for compact, compliance-safe datasets for data testing and masking. AI training & development and enterprise data sharing are also significant segments, with the latter growing steadily as organizations navigate regulatory hurdles in cross-border data exchanges.
By Industry: The BFSI sector leads the market, leveraging synthetic data for fraud detection, risk analysis, and algorithmic trading validation. Healthcare ranks second, using synthetic data for clinical trials, medical image generation, scientific research, and rare disease prediction — and is expected to record the highest CAGR through 2030.
Regional Analysis
North America maintains the largest market share, supported by a dense ecosystem of AI startups, research institutions, and high-tech enterprises generating consistent demand for high-quality synthetic data. Asia Pacific is projected to grow at the highest CAGR, driven by rapid AI/ML adoption, expanding cloud infrastructure, and increasing investments in generative AI. Europe is growing strongly, bolstered by a concentration of synthetic data vendors and growing institutional funding for in-house synthetic data capabilities. The Middle East & Africa and South America are emerging markets benefiting from accelerating digital transformation in BFSI, healthcare, and automotive sectors.
Competitive Landscape
Key players include Datagen, MOSTLY AI, TonicAI, Synthesis AI, GenRocket, Gretel Labs, K2view, Hazy Limited, Replica Analytics, YData Labs, and Sogeti. These companies are investing in strategic partnerships, product launches, and cross-sector collaborations. Notable developments include Gretel.ai's partnership with Illumina for genomics research, Synthesis AI's enterprise dataset launch on the Snowflake marketplace, and Parallel Domain's introduction of the industry's first public synthetic data visualizer for machine learning engineers.
Connect with Our Expert for any Queries: https://www.fortunebusinessinsights.com/enquiry/speak-to-analyst/108433
Conclusion
The synthetic data generation market is among the fastest-growing segments in the broader AI and data technology landscape. Fueled by stringent privacy regulations, the explosive rise of LLMs, and the insatiable appetite of AI systems for high-quality training data, the market is on course to grow nearly eightfold between 2023 and 2030. As accuracy challenges are progressively addressed through advancing generation techniques, synthetic data is poised to become a cornerstone of global AI development infrastructure.


Comments